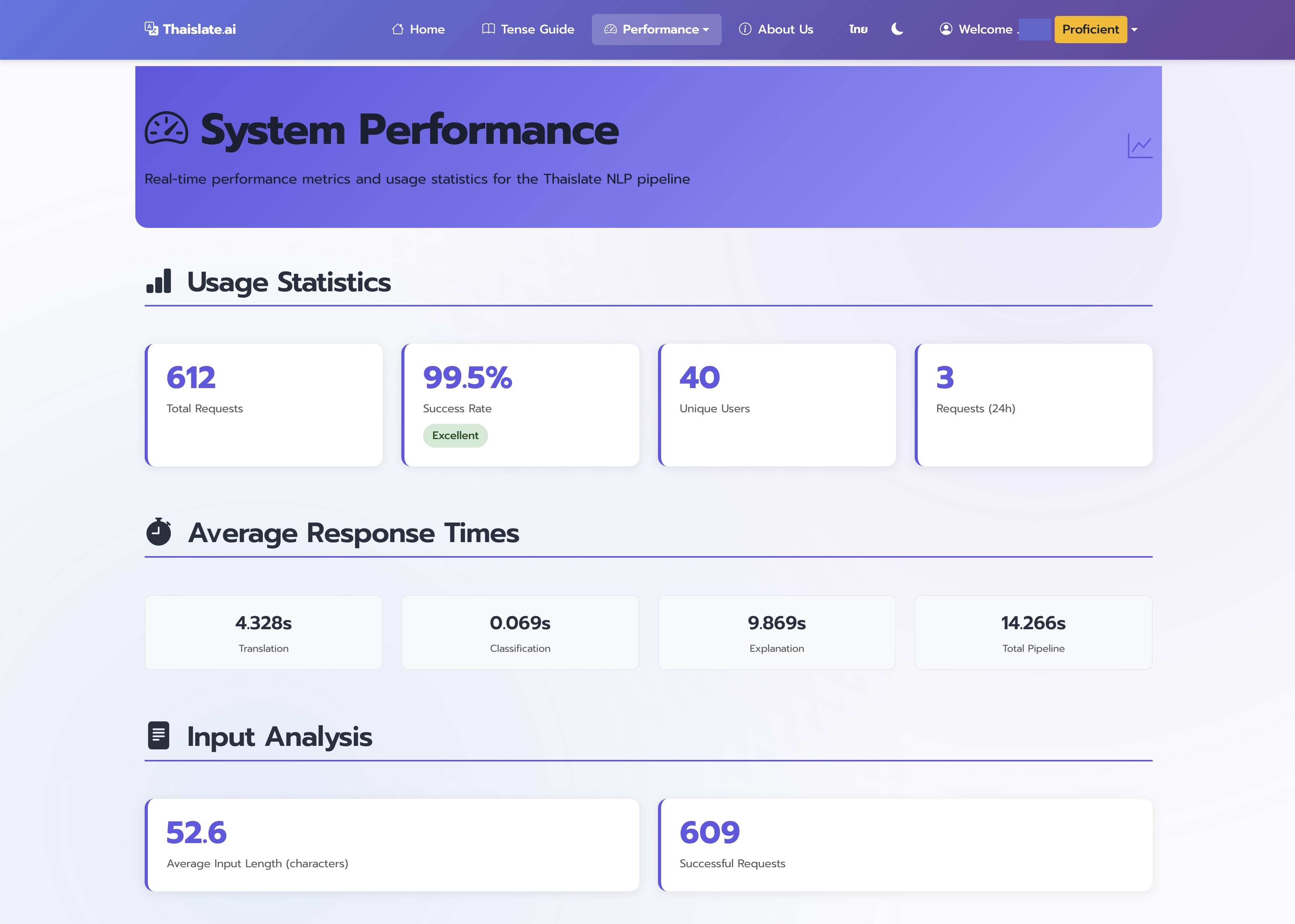
Overview: The disconnect between technical performance (74% pipeline accuracy) and user satisfaction (4.33/5) revealed important insights about what learners truly value in educational technology. This comprehensive evaluation across technical and user dimensions provides crucial insights for the future of educational AI.
Comprehensive Evaluation Framework
The evaluation of Thaislate followed a systematic two-phase approach designed to validate both technical performance and user acceptance of the proof-of-concept system. This dual methodology ensured we understood not just how well the system worked technically, but how much users actually valued it.
Phase 1: Technical Performance Deep Dive
Isolated Model Excellence vs. Pipeline Reality
The custom XLM-RoBERTa hierarchical tense classifier achieved impressive results in controlled testing, but real-world pipeline integration revealed the complexities of educational AI systems.
| Performance Metric | Isolated Model | Pipeline Integration | Impact |
|---|---|---|---|
| Fine-grained Classification | 94.7% | 74.0% | 20.7% degradation |
| Coarse Classification | 97.1% | 92.7% | 4.4% degradation |
| Translation Fluency | N/A | 86.5% | Strong baseline |
| Explanation Correctness | N/A | 84.9% | Educational value maintained |
Classification Performance by Category
Performance varied dramatically across the 24 tense categories, revealing clear patterns based on linguistic complexity:
Performance Tier Analysis
Perfect Performance (100%)
12 categories: BEFOREPAST, DOINGATSOMETIMEPAST, DURATION, EXP, HEADLINE, JUSTFIN, LONGFUTURE, NORFIN, PREDICT, SCHEDULEDFUTURE, SINCEFOR, WILLCONTINUEINFUTURE
These categories have distinct structural markers that are reliably identified by the model.
High Performance (90-99%)
6 categories: 50PERC (91.7%), SUREFUT (92.9%), HABIT (93.3%), RESULT (93.3%), INTERRUPT (94.7%), PROGRESS (94.7%)
Strong performance with minor confusion in semantically similar contexts.
Moderate Performance (80-89%)
4 categories: SAYING (83.3%), FACT (86.4%), RIGHTNOW (87.5%), HAPPENING (88.2%)
Good performance with some contextual confusion patterns.
Challenging Performance (<80%)
2 categories: NOWADAYS (28.6%), PROMISE (60.0%)
Significant challenges with pragmatic and contextual distinctions rather than purely grammatical markers.

Pipeline Integration Challenges
The 20.7% performance gap between isolated and pipeline performance revealed several critical insights about real-world educational AI deployment:
Error Propagation Analysis
- Translation Variability: Classification model receives translated English rather than native English input, introducing linguistic pattern variations
- Domain Shift: Training data consisted of standard English sentences, while pipeline processes Thai-translated English with different characteristics
- Ambiguity Resolution: Thai sentences often lack explicit tense markers, making classification dependent on translation quality
- Context Truncation: Extracting only first sentences ensures focus but may discard valuable temporal context
Phase 2: User Validation Results
The Remarkable Disconnect
Despite technical limitations, users provided overwhelmingly positive feedback. This disconnect between technical performance (74% accuracy) and user satisfaction (4.33/5) reveals a fundamental insight: learners value clear, helpful explanations even when the underlying technology isn't perfect.
Rating Distribution Analysis
The distribution reveals a strong positive skew, with over 75% of evaluations receiving 4 or 5 stars across all criteria:
| Rating (Stars) | Translation Accuracy | Translation Fluency | Explanation Quality | Educational Value |
|---|---|---|---|---|
| 5 Stars | 52.3% | 56.8% | 61.2% | 58.9% |
| 4 Stars | 23.4% | 25.1% | 24.7% | 25.3% |
| 4-5 Stars Total | 75.7% | 81.9% | 85.9% | 84.2% |
Qualitative Feedback Insights
User Tag Analysis
Most Positive Feedback
31.0% of tags: "Perfect translation" - Users appreciated accuracy in Thai-English conversion
Additional positive themes: Clear explanations, helpful examples, accurate tense identification
Primary Issues Identified
Users provided structured feedback on specific improvement areas, with most issues relating to edge cases in tense classification and occasional vocabulary selection
Educational Value Recognition
Consistent positive feedback on the system's ability to explain "WHY" certain tenses are used, validating the core educational philosophy
System Reliability and Deployment Success
Critical Performance Insights
Technical vs. Educational Success
The most significant finding was the disconnect between technical accuracy and user satisfaction. While pipeline classification accuracy dropped to 74%, explanation quality received 4.33/5 ratings. This validates a crucial insight: educational effectiveness isn't purely determined by technical metrics.
Key Learning for Educational AI
Several critical insights emerged from this comprehensive evaluation:
- User Value vs. Technical Perfection: Learners prioritize clear, helpful explanations over perfect accuracy
- Context Matters More Than Precision: Educational context and explanation quality drive satisfaction more than classification precision
- Consistency Beats Complexity: Reliable, consistent responses (even if imperfect) build more trust than inconsistent high-accuracy results
- Pipeline Integration is Complex: Real-world performance significantly differs from isolated model testing
- User Feedback is Generous: When users perceive genuine educational value, they're forgiving of technical limitations
Implications for Future Educational AI
The evaluation results provide valuable guidance for developing educational AI systems:
Design Principles Validated
- Explanation-Centered Design: Focus on clear, educational explanations rather than just accuracy metrics
- User-Centric Evaluation: Technical metrics alone don't predict educational effectiveness
- Transparent Limitations: Honest communication about system capabilities builds more trust than hidden complexity
- Iterative Improvement: Strong user acceptance provides foundation for incremental technical improvements
Performance Success Framework
The Thaislate evaluation establishes a framework for measuring educational AI success across multiple dimensions rather than relying solely on technical metrics. This comprehensive approach provides a more complete picture of system effectiveness in real educational contexts.
Complete the Journey
Explore the technical foundations behind these results: