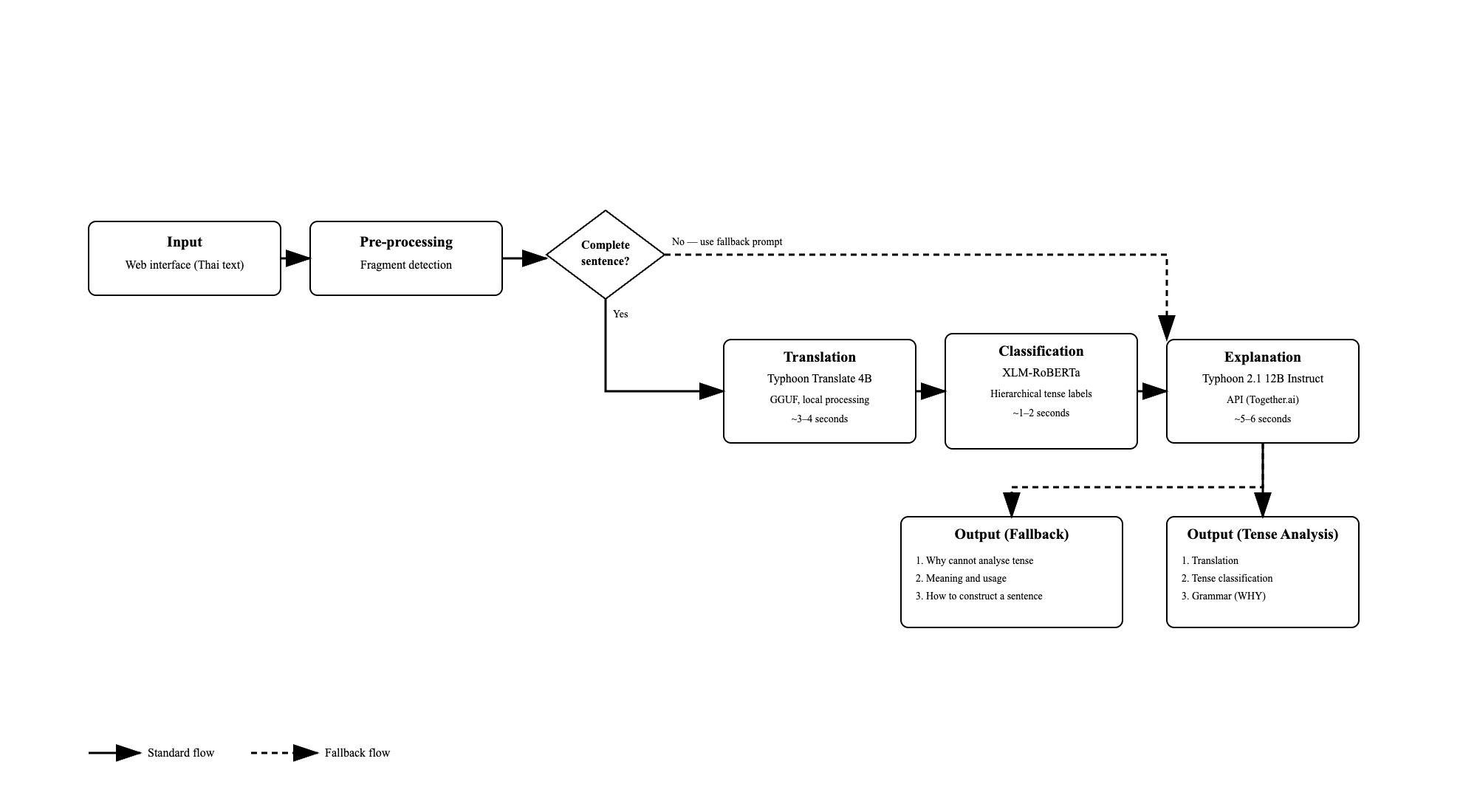
Overview: Thaislate employs a sophisticated three-layer neural pipeline that transforms Thai input into contextual English grammar explanations. This post explores the architecture that emerged through iterative development and the technical decisions that made educational AI possible.
The Evolution of Architecture: A Journey of Discovery
The development of Thaislate wasn't a straight path from conception to implementation. Instead, it represents a journey of discovery where initial limitations revealed the need for specialized approaches, ultimately leading to innovative solutions for educational natural language processing.
Phase 1: The Monolithic Vision
The project began with a straightforward goal: create "an English grammar breakdown thing" using a single, detailed language model. This approach initially seemed logical—instruction-following models had demonstrated capabilities in educational content generation and could theoretically handle both translation and grammar explanation tasks within a unified framework.
The Critical Discovery: During early experimentation, a critical limitation emerged that would reshape the entire project architecture. Instruction-following models, while capable of generating fluent and pedagogically appropriate explanations, consistently misclassified English tenses. This created a devastating problem for educational applications: learners would receive confident, well-structured explanations about incorrect grammatical concepts.
Phase 2: Pipeline Architecture Discovery
The three-stage pipeline architecture emerged organically through trial-and-error within Google Colab's experimental environment. While testing different model combinations and approaches, it became evident that specialized models working in sequence could achieve superior results compared to any single general-purpose system.
Key Insight: Translation → Classification → Explanation as separate, specialized processes outperformed all attempts at unified models. This discovery became the foundation of the entire system design.
Phase 3: Production Reality
The transition from Colab's experimental environment to production deployment revealed numerous practical challenges that shaped the final system architecture. Memory and computational limitations led to several solutions that ultimately improved the system:
- GGUF Quantisation Discovery: Initial attempts to load multiple models exceeded 16GB RAM limits, leading to the adoption of GGUF quantisation that enabled efficient CPU-only inference
- Hybrid Architecture Evolution: Resource constraints drove the hybrid local-API approach, combining local efficiency with cloud-based quality for optimal cost-performance balance
- Thread-Safe Design: Concurrent user access issues necessitated thread-safe model management, improving system reliability beyond initial requirements
Three-Model Architecture: Specialized Excellence
The development journey culminated in a three-model architecture where each component serves a distinct educational function, validated through practical deployment and user testing.

Technical Stack and Implementation
The implementation leverages multiple specialized libraries to create a robust educational platform:
Core Technologies
The Three Specialized Models
1. Translation Model: Typhoon Translate 4B
- Purpose: Convert Thai learner input into analysable English text
- Specialization: Thai-English language pairs with temporal marker preservation
- Key Advantage: 67.2% win rate against major competitors including GPT-4 variants
- Implementation: GGUF quantization for CPU-only deployment
2. Classification Model: Custom XLM-RoBERTa
- Purpose: Identify specific English tense categories (24 classifications)
- Specialization: Thai learner-specific temporal distinctions
- Key Advantage: 94.7% accuracy with consistency across identical inputs
- Innovation: Hierarchical taxonomy designed for educational contexts
3. Explanation Model: Typhoon 2.1 12B
- Purpose: Generate pedagogically appropriate grammar explanations
- Specialization: Educational content tailored for Thai learners
- Key Advantage: Context-aware explanations bridging Thai-English concepts
- Implementation: API-based for optimal quality and resource management
Advantages of the Three-Model Approach
- Task-Specific Optimization: Each model can be fine-tuned for its particular educational function
- Performance Reliability: Higher accuracy than general-purpose alternatives in comparative evaluation
- Independent Improvement: Models can be upgraded or replaced without affecting the entire system
- Computational Efficiency: Resource allocation optimized for each model's specific requirements
Preprocessing Pipeline: Ensuring Educational Quality
Before any model processing occurs, the system implements detailed preprocessing to ensure appropriate educational content and optimal learning conditions:
| Component | Function |
|---|---|
| Educational Content Filtering | Detects inappropriate content using 40+ Thai profanity patterns with exception handling |
| Language Detection | Identifies English vs Thai input through character distribution analysis |
| Token Limitation | Restricts input to 100 tokens maximum for computational efficiency |
| Multi-Sentence Detection | Identifies sentence boundaries using regex patterns for Thai and English |
| Fragment Detection | Validates complete sentence structure including verb presence |
| Graceful Degradation | Enables partial processing with educational feedback when issues occur |
Translation Model Deep Dive
The translation component uses a minimalist prompting approach recommended by the Typhoon model developers:
This simple approach reflects the specialized nature of Typhoon Translate, which was trained specifically for Thai-English translation tasks and achieves optimal performance through direct prompts without complex instructional formatting.
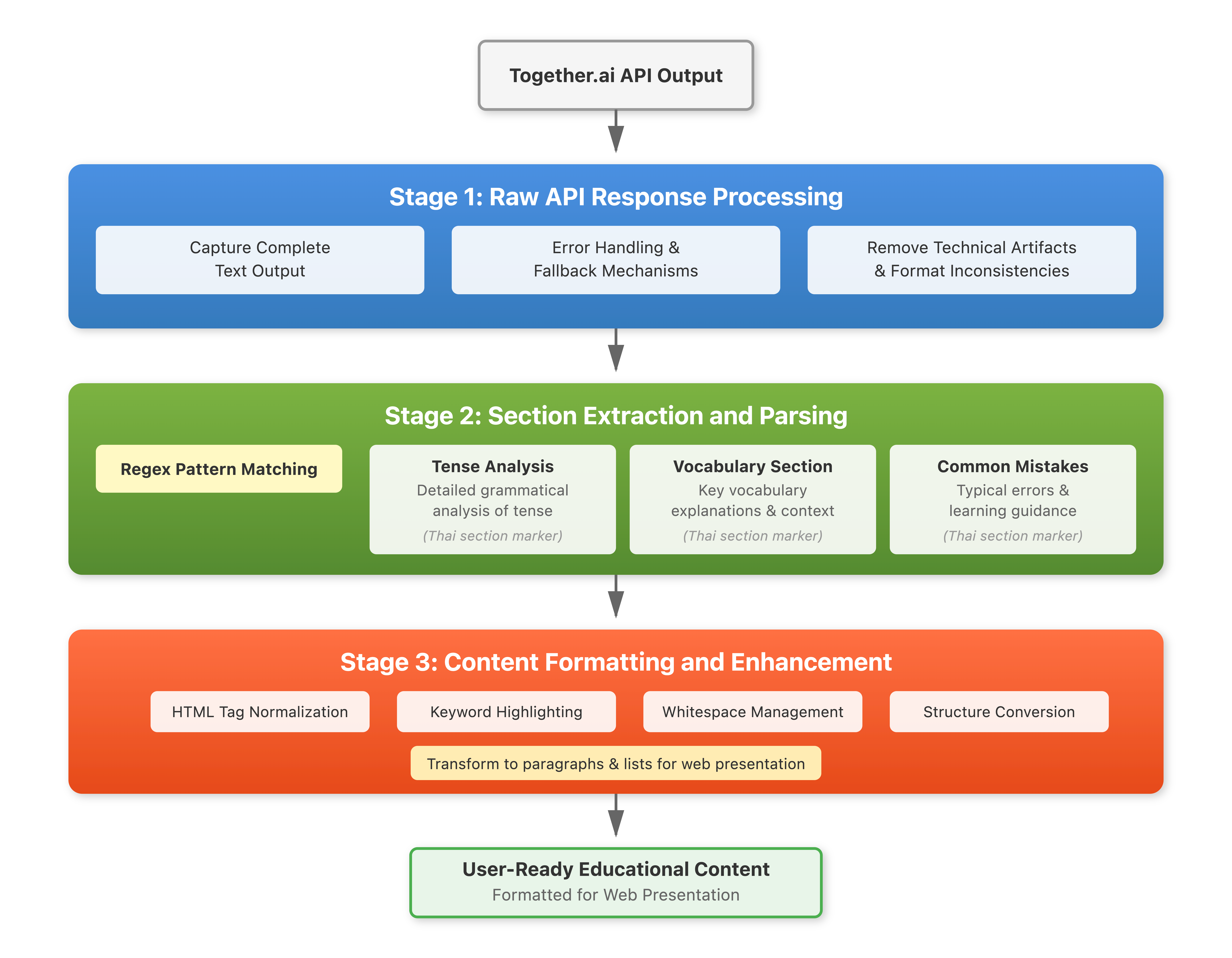
Data Flow and Integration Strategy
The pipeline orchestrates three specialized models in sequential processing to transform Thai learner input into detailed English grammar instruction. The integration strategy emphasizes:
- Data Flow Optimization: Each stage produces output optimized for the next component
- Educational Coherence: Maintaining pedagogical context throughout the processing chain
- Error Propagation Management: Handling failures gracefully while providing educational value
- Context Preservation: Maintaining original Thai context for culturally appropriate explanations
Performance and Reliability
The specialized architecture demonstrates significant advantages over monolithic approaches:
- Translation: 93.2% fluency rating in user evaluations
- Classification: 94.7% accuracy on isolated evaluation, 74% in pipeline integration
- Explanations: 84.9% correctness rating with 4.33/5 user satisfaction
- System Uptime: 99.5% availability during user testing period
Key Insight: Technical vs. Educational Performance
The disconnect between technical performance (74% pipeline accuracy) and user satisfaction (4.33/5) validated a crucial insight: learners value clear explanations even when imperfect. This finding shaped our understanding that educational effectiveness isn't purely determined by technical metrics.
Looking Forward
The three-model architecture establishes a foundation for future educational NLP systems. The specialized approach demonstrates that task-specific optimization can outperform general-purpose solutions in educational contexts, providing a model for similar cross-linguistic learning challenges.
Continue the Journey
Explore more technical details: